In simple terms, Reflexion is a framework that allows AI agents to learn from their mistakes by "talking to themselves". Instead of updating the mathematical weights of the neural network (fine-tuning).
It uses verbal reinforcement to store past failures as memories, creating a "semantic gradient" that guides future actions.
... in other words: "are you sure?"
But, its not a simple ability to "Self-Refine".
In the article "What Our Internal AI Protocol Teaches Us About High-Performance Software Development" [link below], the prompt uses a cognitive mechanism that makes "REFLEXION" effective - the AI's ability to critique its own output. This is comparable to the technique called 'Self-Refine', as a precursor or related technique, but limited to single-generation tasks
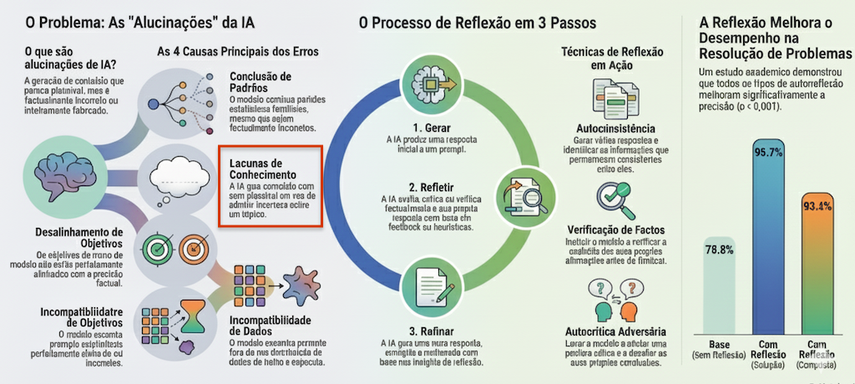
The "Reflexion" uses self-criticism to modify future behavior and update its long-term memory for new attempts - its a little more then just "Self-Refine" ;).
The benefits of Reflexion lies in its ability to overcome critical limitations of traditional Reinforcement Learning (RL) methods and simple prompt engineering to enable LLMs (Large Language Models) to achieve state-of-the-art performance in complex tasks without the need for expensive retraining
-> better results, without complexity and costs
- Compute and Data Efficiency
- Eliminating Hallucinations and Reasoning Errors
- Explicit Interpretability
- Superiority Over Chain-of-Thought (CoT)
Traditional RL requires millions of data samples and expensive model fine-tuning. Reflexion is lightweight, it keeps the underlying LLM "frozen" and only updates the agent's context and memory, saving computational resources.
Reflexion forces the model to adopt a skeptical analysis about its own output, identifying contradictions and correcting flaws before a final answer. This approach helped Reflexion surpass GPT-4’s baseline accuracy on benchmarks like HumanEval (coding) and HotPotQA (reasoning).
Unlike "black-box" neural networks where learning is hidden in millions of numbers, Reflexion stores learning as explicit text.
Humans can read exactly what the agent learned, making the system auditable and more trustworthy. - yeap! we should do it more often
While Chain-of-Thought helps a model reason, it has no mechanism to recover if the initial reasoning is flawed. Using a layer of error detection and memory, Reflexion allowi the agent to pivot and succeed where CoT alone would get stuck.
To better understand the difference between traditional AI training and Reflexion, consider an athlete training for a basketball shot:
In the Traditional Reinforcement Learning (RL): The coach only shouts a number from 0 to 10 after each shot. The athlete must shoot thousands of times to guess, solely from those numbers, how to adjust their strength and angle.
Reflexion: The coach says, "You used too much force and your elbow was too open." The athlete writes this in a noteook, reads it before the next shot, and corrects the movement immediately. They need far fewer attempts because the feedback is explanatory and actionable.
Reflexion is more than a prompt; it is a workflow architecture that empowers AI to refine its own behavior, bringing us closer to agents that can truly learn from experience.
Reflexion: Language Agents with Verbal Reinforcement Learning -
arXiv:2303.11366 [cs.AI]
What Our Internal AI Protocol Teaches Us About High-Performance Software Development